编译器开发-函数声明与调用
函数相关指令分为两类:
- 声明(
function,return) - 调用(
call)
在vm中,是以这种形式使用:
与高级语言不同的是,vm代码中的每一行都会依次执行(除非遇到JMP这类跳转指令,这会改变程序执行顺序),而高级语言在遇到函数声明时,并不会执行函数体内任何代码,只有主动调用时才会执行函数体。
这是因为vm代码是依靠PC来读取下一条指令的(默认情况下PC是自增的,除非遇到JMP这类跳转指令手动更改PC),所以在一份vm代码执行时,首先应该有一段bootstrap代码来引导程序流首先执行main函数(或者其他任意名称)作为vm的主入口,在main中再去调用其他函数。
第一步类似于OS的bootloader,机器上电后给定一个指定位置开始引导初始程序,第二步则类似于C或其他语言的main函数,整个程序的主入口只有main,其他函数则依靠main来调用。
在部分高级语言中,例如C、Python,要想调用一个函数,则函数必须在调用位置之前定义过,也就是不存在“函数提升”。而另一部分高级语言中,例如Go、Rust,你可以任意的在合法的定义域中调用函数,而不用管他们的声明顺序。为什么会有这种区别?可能是语言特性设计上就是不允许先使用后定义,也可能是实现原因导致无法做到。但对于vm或者其他部分底层语言来说,不存在“函数提升”这个概念,因为一切函数皆为地址。
TL;DR
在vm中,函数的调用指令按照下列顺序进行:
- call 开始调用一个函数(callee),调用方(caller)保存现场,接着跳转至函数声明
- function 声明一个函数,进行一些基本的函数初始化,之后执行函数体代码
- return 函数结束,将函数返回值push到栈上,跳转至caller处,恢复现场
在上面的代码中,call 开始调用函数foo,call所处的环境就是caller,foo就是callee,在保存现场后,程序跳转至 function foo 2 处,function执行完必要的初始化指令后,会顺序执行至return,此时函数调用结束,return负责恢复caller的现场,并将程序跳转至call处继续执行。
call
call 指令用于调用一个函数,它的关键工作就是要“保存现场”。通常程序肯定包含不同的函数,彼此嵌套调用,这就需要在函数调用结束后,函数调用方(caller)的环境(例如各种寄存器,栈等)需要恢复到调用之前的状态,这就是通常我们所说的函数调用的开销(当然实际高级语言的环境恢复要比这个复杂,但原理是类似的)。
call 指令的格式为 call functionName nArgs,这表示要调用名为 functionName 的函数,并且已经将nArgs个参数push到栈上,例如 call foo 2 表示调用foo,并且已经将2个参数push到栈上。
接着一步步来跟踪栈的变化,假设目前的栈为

现在想要调用foo函数,并向foo传两个参数,那么首先需要将这两个参数push到栈上。与高级语言不同,vm或者类似的底层语言没有所谓形参/实参的概念,一切数据传递都要依靠计算机中最基本的栈,所以首先需要将两个参数push到栈上。

接着才是call指令真正发挥作用的地方“保存现场并跳转”。
在vm中,环境数据包含LCL,ARG,THIS,THAT这四个内存值,他们分别记录了不同的内存段基址,关于这些内存段的详细信息,见内存布局,这些值与函数本身是息息相关的,所以在callee实际被调用前需要保存他们,那么保存在哪里呢?答案是保存在栈上。同时还要保存这条call指令“完结处”所在的地址,以便return时能够找到正确的返回地址。所以在保存现场后,栈的情况应该是这样:
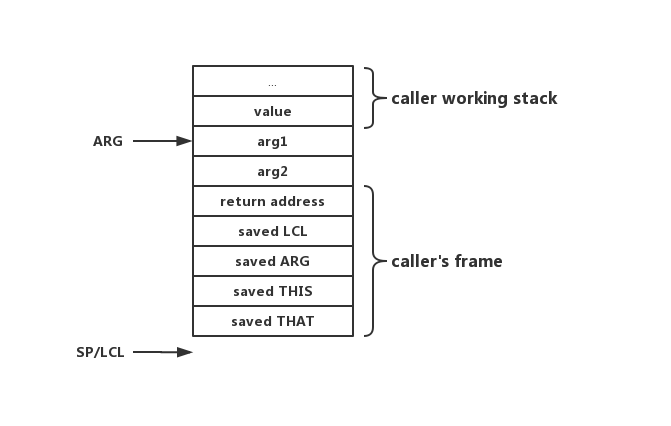
这里有几点需要注意,首先,return address指的是vm的call指令的完结处,但由于vm需要编译为asm才能执行,所以return address的真实地址是call编译为asm后的一系列指令的完结处。在保存return address和环境数据后,这一段数据称为 caller's frame,他们需要在函数执行完毕后销毁。最后,我们还需要将ARG设为第一个参数(arg1)的地址,将LCL设为SP的值。这是因为我们需要依靠ARG指针来获取参数,所以需要将ARG设为arg1的地址;在保存完环境数据后,SP会指向环境数据的下一个位置,此时已经是callee的栈空间了,所以也需要将LCL设为SP。
最后一步,将程序跳转至functionName所在地址,到此,call指令结束,接着程序会由函数functionName接管。
function
函数声明,或者说函数体,由function指令来定义,其指令格式为 function functionName nArgs,表示定义函数functionName,并包含nArgs个本地变量。调用call指令时,它做的最后一件事就是将程序跳转到这条function指令的位置,接着function指令开始执行。function指令相对比较简单,它只负责对函数的局部变量进行初始化,也就是LCL。
function指令会push nArgs个0到栈上,在指令完成后,栈会变成这样:
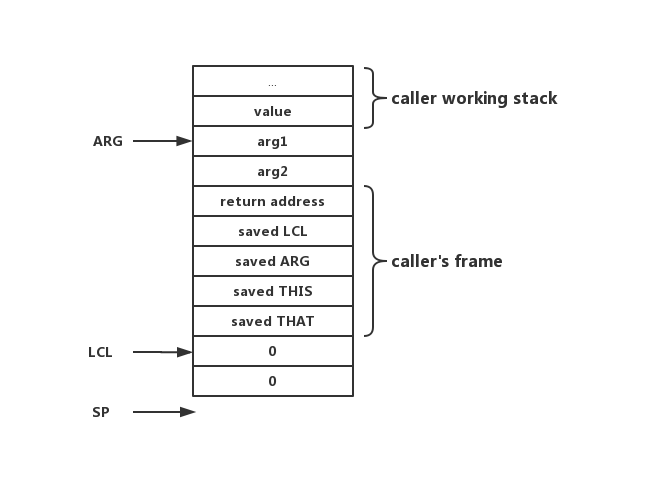
为什么要push nArgs个0到栈上?这是由function指令的语义决定的,那为什么要有这样的语义?因为vm也是自jack编译而来的,在高级语言中,可能有类似这样的代码:
定义了两个局部变量,这两个变量需要在foo函数结束后销毁,而编译jack时可以知道有几个局部变量,那么最好的办法就是将局部变量push到栈上后,通过LCL来读写。在return结束后,所有callee的栈空间都会被销毁,局部变量也就顺便被销毁了。
在执行完上述过程后,function指令就结束了(只干了local变量的初始化)。接着指令(函数体)顺序执行,知道遇到return指令。
有一点需要注意,虽然call/function指令都跟着functionName nArgs,但这两个nArgs的含义完全不同,前者表示push了几个functionName的参数到栈上,后者表示functionName初始化几个local变量,所以实际代码中functionName后的值可能完全是不同的。
return
callee运行时遇到了return指令,说明callee执行结束,经过一段时间的运行,栈的情况可能是这样的:
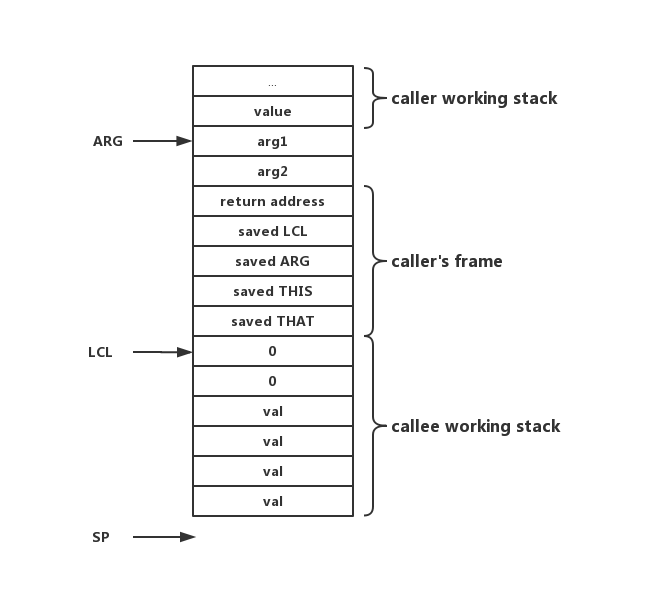
可以看到栈上多了4个val,这部分就是callee的working stack,当遇到了return指令,说明程序结束,程序流需要返回至caller处,并存储返回值。
我们总是假定函数有返回值,并且返回值就是遇到return指令时栈顶的值,这时我们需要将其复制到ARG处。因为函数调用对stack的影响就是pop n个参数,push一个return value,就像add、sub这类指令一样。将return value复制到ARG处,实际上就是完成这一操作。
接着需要把之前保存过的LCL,ARG,THIS,THAT恢复到memory中。
在callee执行完成后,所有因为这次调用而在stack上存储的数据都不再有用,所以需要清理掉这些数据,方法是直接将SP设为ARG的地址+1。整体看stack的表现就是pop了两个参数,push了一个return value。在return指令结束后,栈变成了这样:
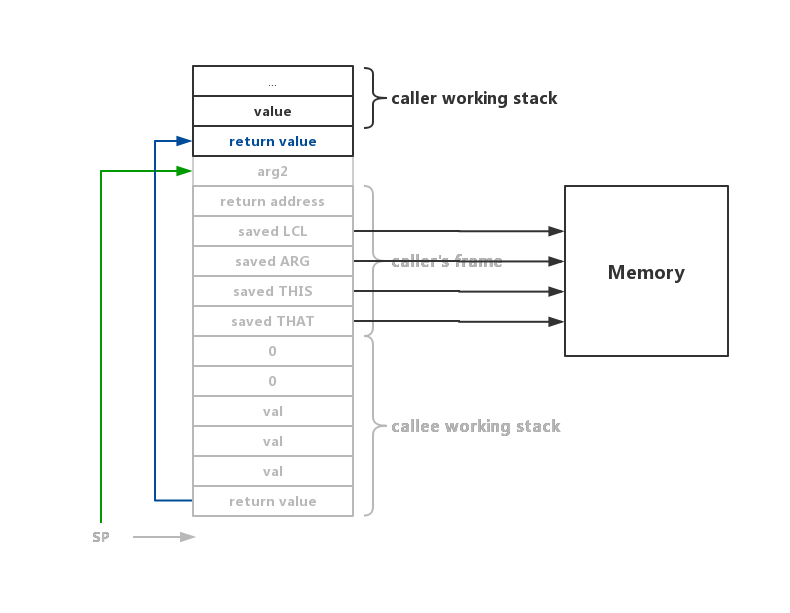
可以看到,return value被复制到原本的arg1处,SP指向了arg2,也就是说自return value后,所有的值均已被销毁。当然销毁之前记得把之前保存的LCL,ARG,THIS,THAT恢复到内存中。
接着进行最后一步,将程序跳转至caller,在call指令调用时我们已经将call指令后一位地址push到栈上了,即return address,所以直接跳转至return address存储的值即可跳转回caller处。到此,函数完整调用过程结束。
与现实世界的联系
以上只是一次函数调用的情况,当有多有函数嵌套调用时,栈的情况就会变得一层叠一层,就像这样

这就是我们常说的“调用栈”,为什么会有stack overflow的错误?就是因为嵌套调用次数太多,要push的数据超出了栈本身的容量。
为什么存在“尾递归”优化?因为编译器主动先pop callee,再push下一个callee(相对于其父caller(具体实现可能有所不同))。
为什么debugger能追踪函数的调用过程?就是因为读取了调用栈。
为什么在一些语言的文档上描述“函数调用其实是往栈上push数据的过程”,因为实际过程就是这样。
理解了这本文,对于语言的函数调用原理基本上就理解的八九不离十了。