V8 Heap Snapshot 格式解析
查看页面堆内存使用情况时,DevTools 的 Memory 面板是最核心的工具。
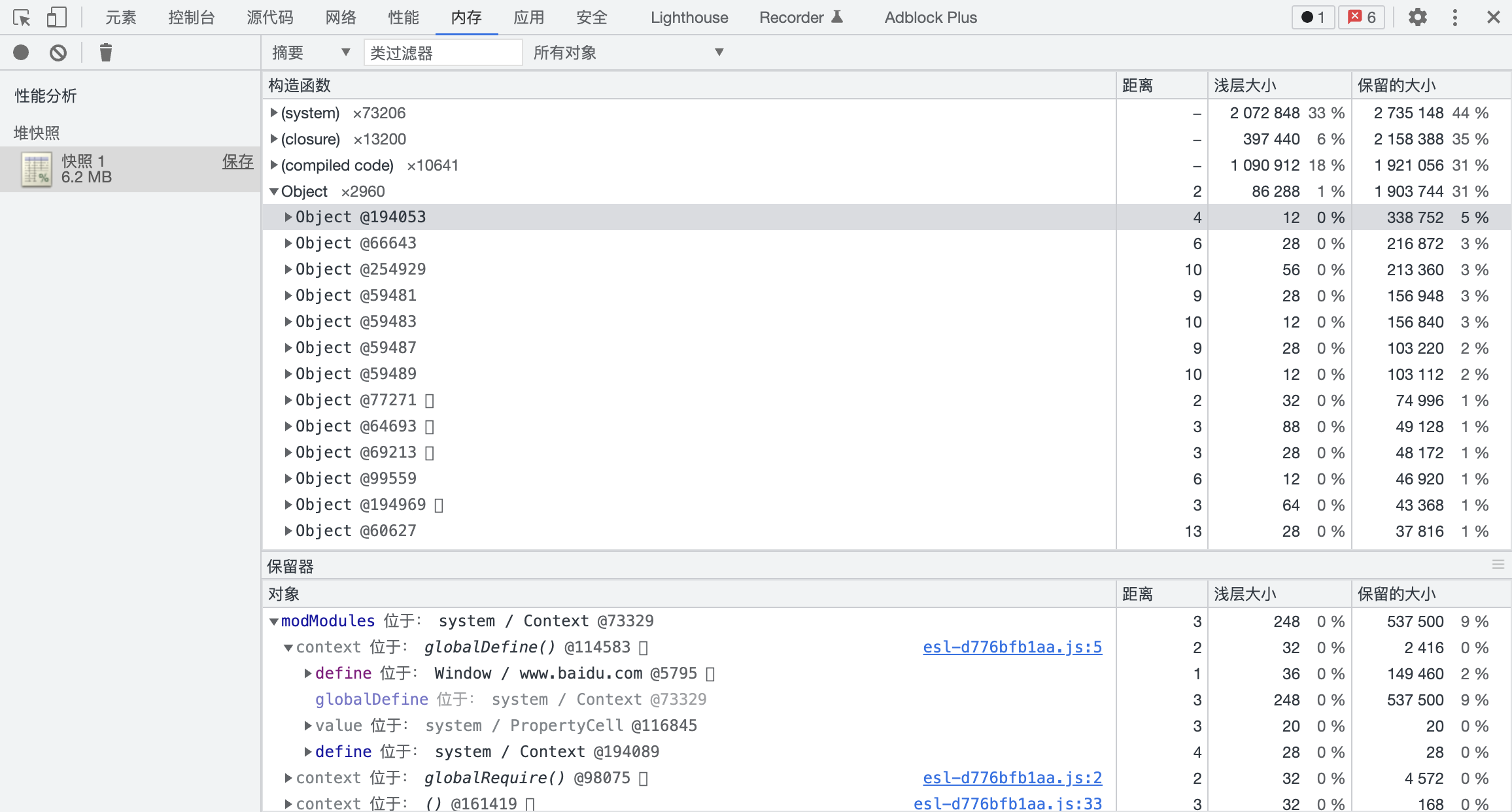
但在超大型前端工程中,有些场景使用 Memory 面板定位堆内存使用情况是不太方便的,典型场景例如:
- 堆内存字符串常量池中有上百万个字符串,这些字符串可能被不同的对象持有,在 Memory 面板中无法知道这些字符串持有对象的分布。
- 一次只能查看一条持有链,例如上图中 Object@194053 可以看到被谁持有,以及持有谁,但都是以 Object@194053 为核心的,如果有一个较大的循环引用,往往很难发现
- 没有方便的过滤、排序选项
但所幸 DevTools 支持将堆内存快照保存为文本格式,点击保存按钮就会保存当前快照为 *.heapsnapshot 文件,这就使我们编写自定义分析程序成为可能,分析的第一步就是要了解并解析 heapsnapshot 文件中的关键数据。
堆内存结构
在开始分析文件结构前,先简单了解下堆内存的结构。
上图是视觉上的堆内存表示,堆内存中一个对象有两种方式来占用一些内存:
- 对象自身直接占用内存
- 对象持有别的对象,使别的对象无法被 GC 掉,从而间接占用内存
对象之间可以互相引用,不论是通过属性链接到另一个对象上,还是将另一个对象存在自己的数组里,本质上都是建立了对象之间的引用关系,这些引用关系就如同上图一样,所以堆内存结构本质上就是一张 “有向图”,我们解析 heapsnapshot 文件就是要把这张 “有向图” 从数据中发掘出来。
heapsnapshot 文件结构
heapsnapshot 是纯文本文件,可以直接使用文本编辑器打开。打开后可以看到它其实是一份 JSON 文档。
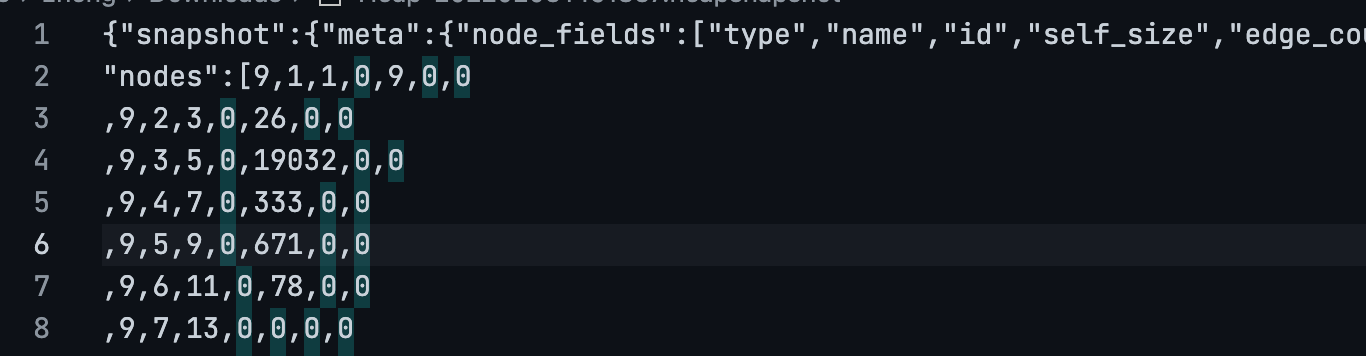
既然是 JSON 文档,那就能用 JS 直接读它并在 DevTools 里查看:
1const [fh] = await window.showOpenFilePicker();
2const fp = await fh.getFile();
3const reader = new FileReader();
4reader.onload = () => console.log(JSON.parse(reader.result))
5reader.readAsText(fp);

heapsnapshot 文件中核心字段有四个:
- nodes - 存储所有顶点数据,每一个顶点是堆内存中最小的原子结构
- edges - 存储所有边的数据,边连接两个顶点
- snapshot - 这份 snapshot 文件的元数据,包含顶点数量、边数量、顶点字段类型、边字段类型等
- strings - 所有字符串数据,例如顶点名称,类型名称等
nodes
首先看一下 nodes 序列化时的结构,从 HeapSnapshotJSONSerializer::SerializeNode
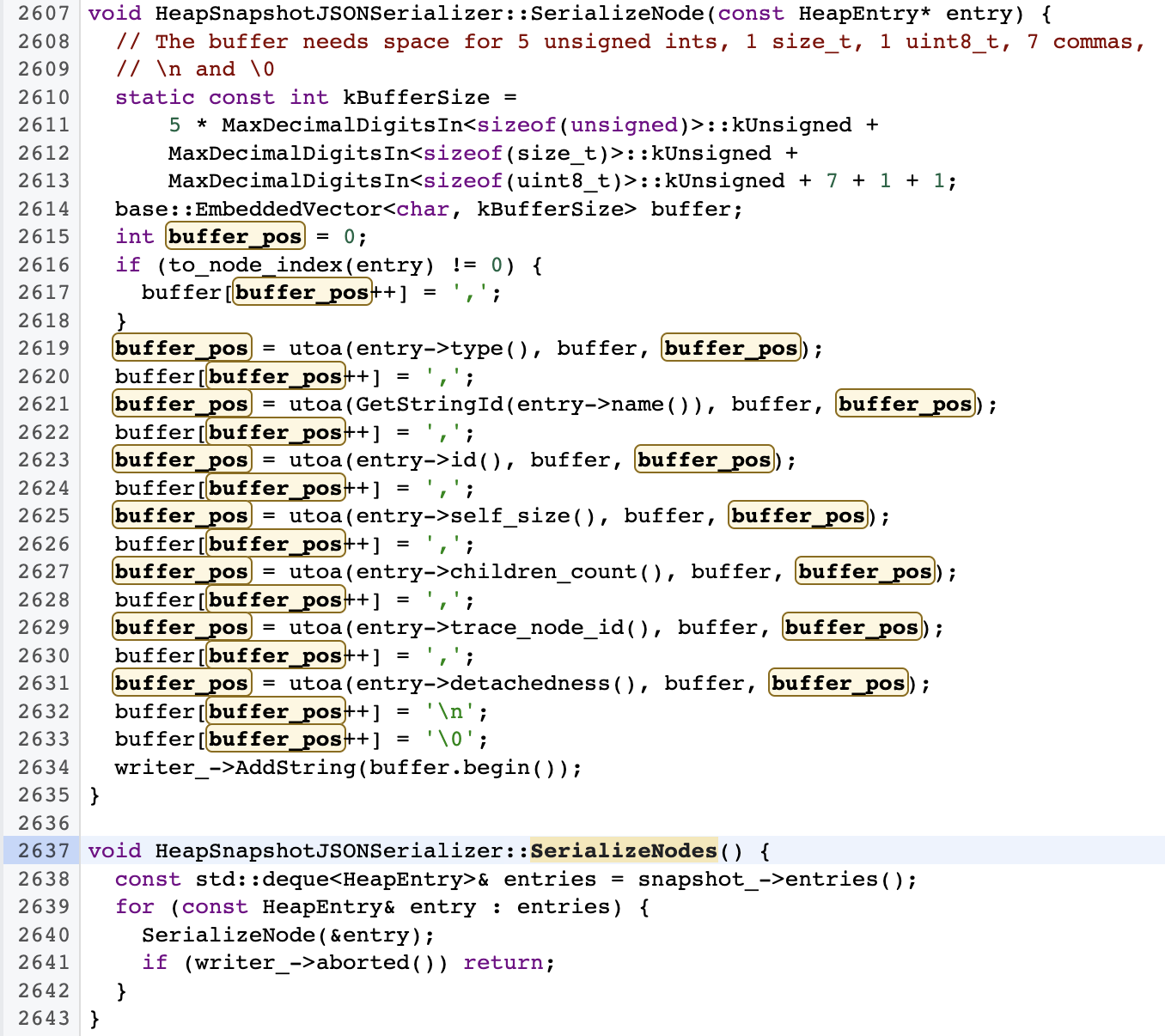
方法中可以看到,V8 会把每个顶点的7个属性按顺序保存下来,也就是说在 nodes 数组中,每 7 个值属于一个顶点,他们的值都是数字,却有不同的含义。 snapshot.node_count * snapshot.meta.node_types.length 的结果正是 nodes.length。
这7个属性值分别是
- type - 节点类型,它是 snapshot.meta.node_types[0] 的索引
- name - 节点名称,它是 strings 的索引
- id - 节点 id, 这个 id 是 V8 Snapshot 对象的id,也就是上图中
Object@194053@ 后面的值,该 id 在一个 V8 实例中全局唯一 - self_size - 节点自身尺寸
- edge_count - 起点为该节点的边的数量
- trace_node_id - 可以暂时不管,正常方式启动 Chromium/Chrome 后该字段值始终为 0,只有启动时带上参数
--track-heap-objects才不为0,用于定位该对象创建的调用栈 - detachedness - 可以暂时不管,它表示对象是否从主应用中分离(detached),通常都是 0,表示 unknown
看到这里堆 nodes 的结构就很清晰了:

简单的伪代码就是:
1for node_base_idx in (0..all_nodes.len()).step_by(meta.node_fields.len()) {
2 nodes.push(Node {
3 node_type: meta.node_types[0].get_value(all_nodes[node_base_idx] as usize),
4 name: self.get_string(all_nodes[node_base_idx + 1] as usize),
5 id: all_nodes[node_base_idx + 2],
6 self_size: all_nodes[node_base_idx + 3],
7 edge_count: all_nodes[node_base_idx + 4],
8 trace_node_id: all_nodes[node_base_idx + 5],
9 detachedness: all_nodes[node_base_idx + 6],
10 })
11}
node 是 Heap 中的实体的映射,所以 node 会有不同的类型。正如前面提到的,node 的类型存储在 snapshot.meta.node_types 中,它们分别是:
- hidden: 隐藏类型
- array: 数组
- string: 字符串
- object: 除数组与字符串外的 JavaScript 对象
- code: 编译后的代码
- closure: 函数闭包(是的,函数闭包不只是一个语法结构,它也存在于堆内存中)
- regexp: 正则表达式
- number: 存储在堆中的数字
- native: 非 V8 引入的 Native 对象
- synthetic: 合成对象,通常用于打包多个 snapshot 中的项目
- concatenated string: 串联的字符串(一对指向字符串的指针)
- sliced string: 字符串切片(另一个字符串的片段)
- symbol: ES6 中的 Symbol
- bigint: BigInt
node name 也与 node type 相关联。前文提到,name 也是 node 上的一个属性,表示这个节点的名称,但 name 属性的真实含义是相对于 node type 的。
- 如果 node type 为 object,则 node name 为它的 constructor name
- 如果 node type 为 closure,则 node name 为闭包函数名称
- 如果 node type 为 string,则 node name 为 string value
edges
看懂了 nodes 的结构,edges 的结构就好理解多了,与 nodes 类型,edges 也是三个值组成一个 edge,这三个值分别是:
- type - 边的类型,它是 snapshot.meta.edge_types[0] 的索引
- name_or_index - 边的名称索引或自身索引
- 如果边的类型为 element 或 hidden,则其值为自身索引,表示目标节点在源节点中的位置
- 否则就是名称索引,表示边的名称,值为 strings 的索引
- to_node - 边的目标节点索引
唯一的问题是,heap snapshot 是一张有向图,但 edges 中只记录了一条边的 「终点」(to_node),没有 「起点」(from_node),这样的图是不完整的。那么边与它的起点是如何对应的呢,这需要再看一下 HeapSnapshotGenerator::FillChildren。
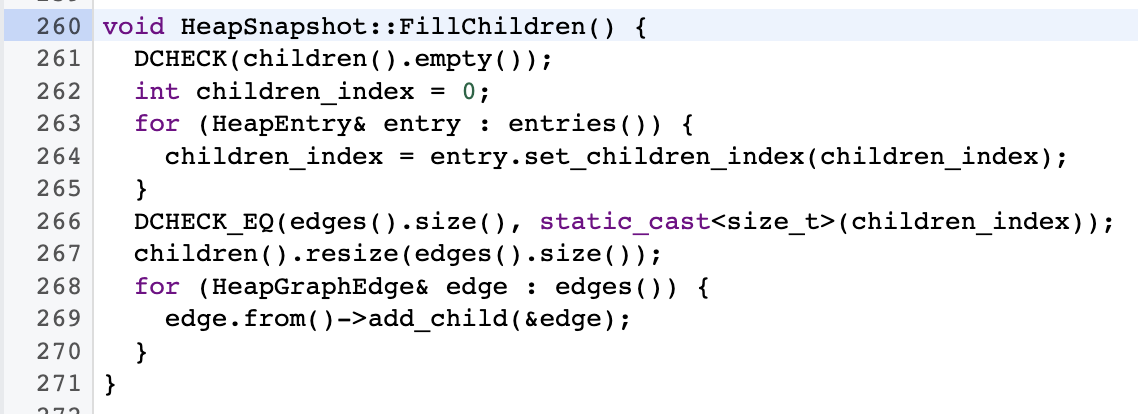

大致的逻辑是:
- FillChildren 按顺序遍历每一个 node 时,记录从该 node 出发有多少条边,并输出
- FillChildren 按顺序遍历每一个 edge 时,并输出
所以 node 与 edge 的关系就是:

- 每一个 node 的 edge_count 为几,说明它有几条边
- edges 是 nodes 的映射,node 的 edge_count 时几,在 edges 中就有几条边的起始节点是该 node
例如上图中:
- node0 的 edge_count 为 3,edges[0..3] 的 from_node 就是 node0
- node1 的 edge_count 为 1, edges[3] 的 from_node 就是 node1
- node2 的 edge_count 为 0, edges 中没有起点为 node2 的边
- node3 的 edge_count 为 1,edges[4] 的 from_node 就是 node3
简单的伪代码就是:
1let mut edge_from_node_idx = 0;
2let mut edge_from_node_acc = 0;
3
4// 按 edge_fields 的长度,步进解析每一条边
5for (edge_idx, edge_base_idx) in (0..all_edges.len())
6 .step_by(meta.edge_fields.len())
7 .enumerate()
8{
9 // 边的基础信息
10 let edge_type = meta.edge_types[0].get_value(all_edges[edge_base_idx] as usize);
11 let edge_name_or_index = self.get_string(all_edges[edge_base_idx + 1] as usize);
12 let edge_to_node_idx = all_edges[edge_base_idx + 2] as usize / nodes_fields_count;
13
14 // 忽略 edge_count 为 0 的节点
15 while nodes[edge_from_node_idx].edge_count == 0 {
16 edge_from_node_idx += 1;
17 edge_from_node_acc = 0;
18 }
19
20 // 设置边的起点/终点
21 let edge_idx = edge_idx as u32;
22 nodes[edge_from_node_idx].to_edge_index.push(edge_idx);
23 nodes[edge_to_node_idx].from_edge_index.push(edge_idx);
24
25 let from_node_id = nodes[edge_from_node_idx].id;
26 let to_node_id = nodes[edge_to_node_idx].id;
27
28 edges.push(Edge {
29 edge_type,
30 name_or_index: edge_name_or_index,
31 to_node_index: edge_to_node_idx,
32 to_node_id,
33 from_node_index: edge_from_node_idx,
34 from_node_id,
35 });
36
37 edge_from_node_acc += 1;
38
39 // 如果当前边的累加值超过 edge_count,则重置累加器,边索引 +1
40 if edge_from_node_acc >= nodes[edge_from_node_idx].edge_count as usize {
41 edge_from_node_idx += 1;
42 edge_from_node_acc = 0;
43 }
44}
edge 是 heap 中两个实体的关系映射,例如对象引用、数组引用等。同样,edge 也有多种类型:
- context 表示目标来源于一个 function context
- element 表示目标是一个数组中的元素
- property 表示目标是一个对象上的属性
- internal 内部引用,这种引用无法被 JavaScript 访问,例如 concatenated string
- hidden 这种连接在计算持有尺寸时需要,但不对用户暴露
- shortcut 这种连接在计算持有尺寸时需要排除
- weak 弱引用连接